Computation Framework’s documentation¶
Conduct a research activity that implies modelling complex system and/or find optimal parameters in variational methods could be demanding in terms of time and resources. This is even more evident in the quantum computing realm, in this period of near term devices we are used to benchmark our methods with classical simulations.
This framework was born when we started our research project published here: link. We realized soon that the way we organized our simulation to exploit the usage of server/cluster or HPC environment could have been generalised to several use cases. For those reasons we publish it here so that we could be of help for researchers in their daily activities. The large amount of research project are conducted in teams and this implies having more than one environment and also data generated and/or collected by different people, could be a problem without having a centralized repository. For this reason we decided to design and build a flexible and light weighted system capable to be used by different people enabling data collection according to the same rules and structures. The main research tasks are split into three different pieces:
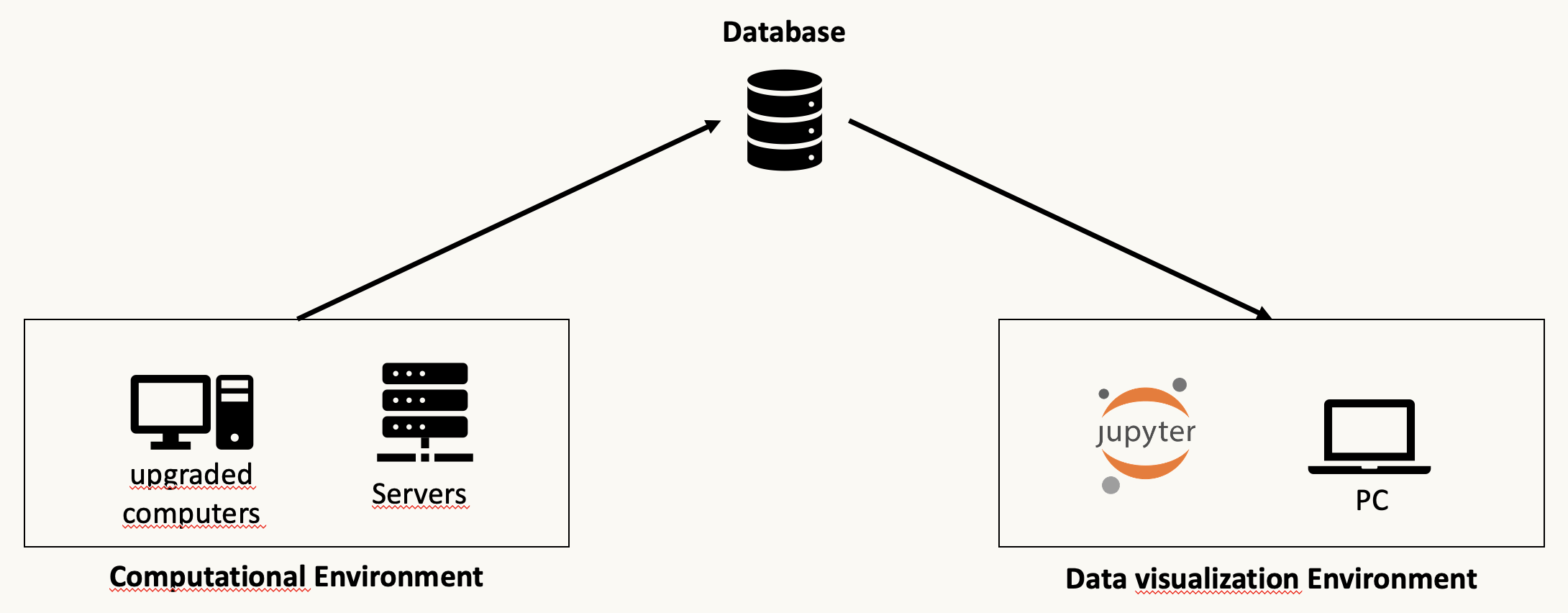
The first part enables parallel calculation on ‘computational environment’, the second part is related to the managing of data, and for this framework we provide facilities to connect the IBM Cloud cloudant database. The third part consists retrieving information from the database and eventually implement some plot functions where the user can manipulate data using a simple jupyter notebook or his own python script.
Data calculation¶
This part is dedicated to the intensive numerical calculation (real quantum devices or simulated on classical devices). Usually this part is conducted on upgraded computers, HPC clusters or quantum cloud devices. Some simulated calculation need a huge amount of memory and execution time and with this tool we can keep our results organized and structured avoiding to lose results or manually move files through different environments. Moreover, in this configuration the obtained results are available to the whole team that have access to the database and with the possibility to configure also a dashboard.
Data collection¶
We decided to collect all the obtained results on a No-SQL json based database because the collection and serialization of data using the json format is the easiest way on a python class. In this direction we defined a json attribute named final_json on the constructor function of the metaclass to collect all the metadata coming from the performed run. We give the user the possibility to save all the results (raw and post processed) as a new record on the database at the end of the calculation.
Warning
Remember to fill the final_json attribute with only
serializable elements , otherwise the db saving will fail
Data Plot¶
This last part of the framework component is dedicated to retrieve data from the database and create plot and reports in order to transform data for a most effective communicative power. In this framework also this part has been written in python in order to be used in the jupyter environment to allow an easy and quick implementation of post processing of saved data and provide graphical representation.
Considering that data are produced and stored in near real time and that each plot is built quering the database, we could say say that each plot is a live report of the obtained results.